After some days' studying and developing, I finally completed a pure javascript litecoin miner. This may be used on website without affecting user experiences for implementing with web worker technique.
If your web site has many more users, it will bring more profit for you.
If interested, please contact martinking1997@gmail.com.
I hosted the codes on https://github.com/martinking1997/web-js-litecoin-miner
Recently I have updated for mass pageviews with share memory and Fine-grained work.
Friday, February 28, 2014
Saturday, December 21, 2013
I built and packaged Hyepric HQ 5.8, please download...
In December, VMWare released the VCenter Hyperic 5.8. So maybe Hyperic Community Edition matured.
At sf.net and official website, HQ v5.8 is silent.
I built , package and upload to the internet.
Please enjoy it:
http://pan.baidu.com/s/1c0CFl5I
for all including aix and hpux agent.
the discussion site is http://hq.innovatedigital.com/
At sf.net and official website, HQ v5.8 is silent.
I built , package and upload to the internet.
Please enjoy it:
http://pan.baidu.com/s/1c0CFl5I
for all including aix and hpux agent.
the discussion site is http://hq.innovatedigital.com/
Monday, December 9, 2013
Nutch 1.7 or Nutch 2.1, setting nutch 1.7 environment
Is nutch1.7 enough for about 100,000 pages? I try it.
2013-12-07 11:26:08,540 INFO parse.ParseSegment - Parsed (0ms):http://www.bjmm.org.cn/outpart/managerarticle.do?method=page&articleId=1651
2013-12-07 11:26:08,545 WARN mapred.LocalJobRunner - job_local1202925054_0001
java.lang.Exception: java.lang.OutOfMemoryError: unable to create new native thread at org.apache.hadoop.mapred.LocalJobRunner$Job.run(LocalJobRunner.java:354)
The valuable stuff is not always too immense. When I crawled less than 300 websites, It occupy less than 1G. If you have limited resource with CPU and memory, nutch 1.7 is good.
So I think nutch 1.7 fits this.
I set up nutch1.7 with solr4.6. And there was some problems.
- nutch reported:
2013-12-07 11:26:08,540 INFO parse.ParseSegment - Parsed (0ms):http://www.bjmm.org.cn/outpart/managerarticle.do?method=page&articleId=1651
2013-12-07 11:26:08,545 WARN mapred.LocalJobRunner - job_local1202925054_0001
java.lang.Exception: java.lang.OutOfMemoryError: unable to create new native thread at org.apache.hadoop.mapred.LocalJobRunner$Job.run(LocalJobRunner.java:354)
Solution Wrong: set fetcher.parse to true and fetcher.store.content to false It did not help.
Solution Right: modify some codes as https://issues.apache.org/jira/browse/NUTCH-1640?jql=project%20%3D%20NUTCH%20AND%20text%20~%20%22create%20thread%22
Some thing like:
in file src/java/org/apache/nutch/parse/ParseSegment.java
private ParseUtil parseUtil = null;
replace parseResult = new ParseUtil(getConf()).parse(content); with
if (parseUtil == null)
parseUtil = new ParseUtil(getConf());
parseResult = parseUtil.parse(content);
Ant and run again. It works.
- What php client is proper? Solarium , Solr-client-php,...
Solarium is good for updating recently.
Tuesday, November 26, 2013
Setting up nutch 2.2.1 with some problems
These days I am setting up a search engine for some official websites. It is only because when I search for technical anwsers, the confusions of the results lead to many wrong ways. Finally, I find the official documents is more valuable than discussions, blogs ...
So I followed the official document at
http://wiki.apache.org/nutch/Nutch2Tutorial
If you want to encounter less problems, please follow that strictly. Hbase-0.90 has to be used.
If you have no idea on Nutch, It is better to follow http://wiki.apache.org/nutch/NutchTutorial first. Some important configuration should be set .
Below are some problems I had.
bin/crawl /home/nutch/apache-nutch-2.2.1/urls/seeds.txt mmtest http://localhost:8983/solr/ 10
It reports:
SolrIndexerJob: starting
Adding 11 documents
Adding 11 documents
SolrIndexerJob: java.lang.RuntimeException: job failed: name=[mmtest]solr-index, jobid=job_local1440285148_0001
at org.apache.nutch.util.NutchJob.waitForCompletion(NutchJob.java:54)
at org.apache.nutch.indexer.solr.SolrIndexerJob.run(SolrIndexerJob.java:46)
So I followed the official document at
http://wiki.apache.org/nutch/Nutch2Tutorial
If you want to encounter less problems, please follow that strictly. Hbase-0.90 has to be used.
If you have no idea on Nutch, It is better to follow http://wiki.apache.org/nutch/NutchTutorial first. Some important configuration should be set .
Below are some problems I had.
- when run
bin/crawl /home/nutch/apache-nutch-2.2.1/urls/seeds.txt mmtest http://localhost:8983/solr/ 10
It reports:
SolrIndexerJob: starting
Adding 11 documents
Adding 11 documents
SolrIndexerJob: java.lang.RuntimeException: job failed: name=[mmtest]solr-index, jobid=job_local1440285148_0001
at org.apache.nutch.util.NutchJob.waitForCompletion(NutchJob.java:54)
at org.apache.nutch.indexer.solr.SolrIndexerJob.run(SolrIndexerJob.java:46)
solution:
copy the schema.xml to solr dir
- when run again
It reprots:
13033 [coreLoadExecutor-3-thread-1] ERROR org.apache.solr.core.CoreContainer ? Unable to create core: collection1
org.apache.solr.common.SolrException: Plugin init failure for [schema.xml] fieldType "text": Plugin init failure for [schema.xml] analyzer/filter: Error loading class 'solr.EnglishPorterFilterFactory'. Schema file is /home/nutch/solr-4.5.1/example/solr/collection1/schema.xml
Solution:
Use SnowballPorterFilterFactory with language="English" instead of EnglishPorterFilterFactory
- run the crawl again
5377 [coreLoadExecutor-3-thread-1] ERROR org.apache.solr.core.CoreContainer ? Unable to create core: collection1
org.apache.solr.common.SolrException: Unable to use updateLog: _version_ field must exist in schema, using indexed="true" stored="true" and multiValued="false" (_version_ does not exist)
Solution:
insert below line into the schema.xml
<field name="_version_" type="long" indexed="true" stored="true" multiValued="false"/>
- run the crawl again
4764 [searcherExecutor-4-thread-1] ERROR org.apache.solr.core.SolrCore ? org.apache.solr.common.SolrException: undefined field text
at org.apache.solr.schema.IndexSchema.getDynamicFieldType(IndexSchema.java:1235)
Solution:
in solrconfig.xml, change <str name="df">text</str> to
<str name="df">content</str>
Now It worked.
Saturday, November 23, 2013
About Hyperic HQ 's future
I have followed the hyperic for some years. After Hyepric HQ was acquired by SpringSource and then by VMWare, it is on its specific road , it turn to be "VMware vCenter Hyperic". The future of opensource version is more vague...
Tuesday, November 12, 2013
Developing Hyperic HQ Plugin to moitor Apache Solr
Apache Solr is so popular, some ones look for the monitoring tools.
Because it is opensource, so the monitoring solution should be opensource tool. Then we developed the plugin based on hyperic hq occupied by VMWare.
Current plugin supports Solr v3.6, if other versions arevrequired, please contact us,
Some metrics are below:
JVM Metrics
activeThreadCount
CurrentHeapSize
TotalHeapSize
Searcher Metrics
Searcher Number of Docs
Searcher Max Docs
Query Metrics
Query Result Cache Evictions
Query Result Cache Hit Ratio
Query Result Cache Hits
Query Result Cache Inserts
Query Result Cache Lookups
Query Result Cache Sizes
Document Metrics
Document Cache Evictions
Document Cache Hit Ratio
Document Cache Hits
Document Cache Inserts
Document Cache Lookups
Document Cache Sizes
Filter Metrics
Filter Cache Evictions
Filter Cache Hit Ratio
Filter Cache Hits
Filter Cache Inserts
Filter Cache Lookups
Filter Cache Sizes
Update Metrics
Update Handler Adds
Update Handler Commits
Update Handler Autocommits
Update Handler Optimizes
Update Handler Rollbacks
Update Handler ExpungeDeletes
Update Handler DocsPending
Update Handler DeletesById
Update Handler DeletesByQuery
Update Handler Errors

Filter Cache Evictions
Filter Cache Hit Ratio
Filter Cache Hits
Filter Cache Inserts
Filter Cache Lookups
Filter Cache Sizes
Update Metrics
Update Handler Adds
Update Handler Commits
Update Handler Autocommits
Update Handler Optimizes
Update Handler Rollbacks
Update Handler ExpungeDeletes
Update Handler DocsPending
Update Handler DeletesById
Update Handler DeletesByQuery
Update Handler Errors

Is it enough? if not, please contact me.
I provide services on installing and setting.If interested, contact martinking1997@gmail.com
Enjoy.
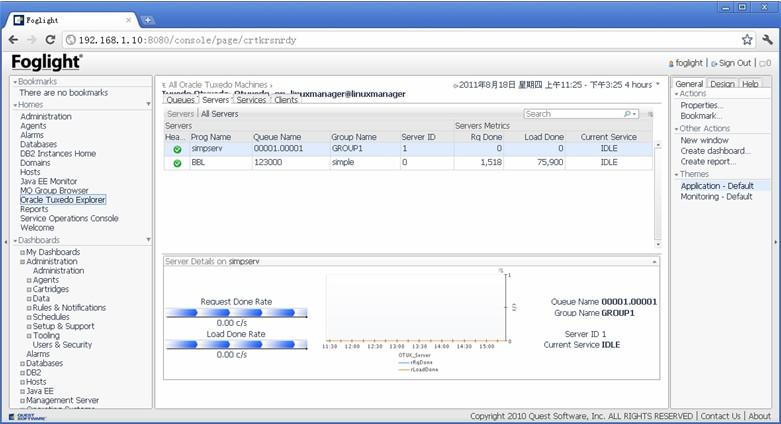
Developing and improving Foglight Cartridge for Oracle Tuxedo
There is no out of box cartridge for tuxedo in Dell Foglight. So we developped one to monitor it. This cartridge contains good views, rules,reports to help monitor it.
Key Metrics Monitored
1。ServersProgram Name,Queue Name,Group Name, Server ID, Requests Done, Load Done,Current Service
2。Services
Service Name, Routine Name, Proggram Name, Grp Name,Server ID, Machine, Requests Done, Status
3.Queues
Proggram Name, Queue Name, Servers on Queue, Wk Queued, Queued Service, Average Length, Machine
4.Clients
LMID, User Name, Client Name, Time, Status, Transactions Begun,Transactions Committed,Transactions Aborted
5.Tuxedo Common Information
Availability, Version, Total Requests, Total Queues Length
Interfaces of Views
1。Tuxedo ExplorerThe view dispplays availability status, health, version, alerts and amount of resources for each Tuxedo instance.
Subscribe to:
Posts (Atom)